Distributed Monitoring¶
High availability and load balancing out-of-the box
Classification availability¶
The classification of systems in terms of availability commonly leads to 7 classes, not taking into account class ( system available 90 % of the time , and therefore unavailable more than one month a year ) to the ultra class (available 99.99999 % of the time and therefore unavailable only three seconds per year) : these classes are the number 9 in the percentage of time that the class systems are available
| Type | Downtime (per year) | percentage availability | class |
| unmanaged | 50,000 ( 34 days , 17 hours and 20 min) | 90 % | 1 |
| managed | 5000 ( 3 days , 11 hours and 20 min) | 99 % | 2 |
| well managed | 500 ( 8:20 minutes) | 99,9 % | 3 |
| fault tolerance | 50 (a little less than an hour ) | 99,99 % | 4 |
| high availability | 5 minutes | 99,999 % | 5 |
| very high availability | 0,5 (30 secondes) | 99,9999 % | 6 |
| high critical availability | 0,05 (3 secondes) | 99,99999 % | 7 |
Introduction¶
A server can fail, and so does the network. That’s why you can (should) define multiple processes as well as spares in the Naemonbox architecture. Monitoring complex environments has never been easier. Activate the built-in cluster feature and you can begin configuring your high availability and distributed monitoring setup.
High availability clusters¶
In Naemonbox, clustered instances assign an ‘active zone master’. This master writes to the Mysql database and manages configurations, notifications and check distribution for all nodes. Should the active zone master fail, another instance is automatically assigned to this role. Furthermore, each instance carries a unique ID to prevent conflicting database entries and split-brain behaviour. With continuous synchronisation of program states as well as check results, this design gives Naemonbox the edge over active-passive clusters using Pacemaker in Nagios. It also makes fail-safe monitoring much easier to scale in Naemonbox
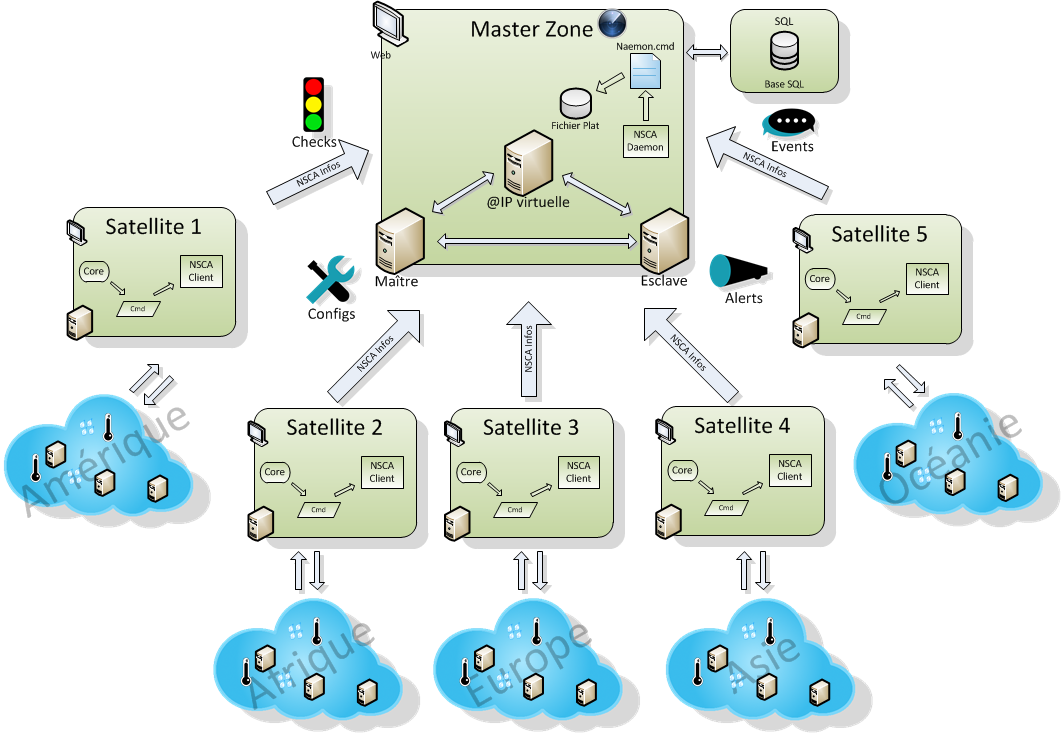
Distributed monitoring¶
Where operations are dispersed across multiple sites, Naemonbox enables distributed monitoring too. Thanks to Naemonbox cluster zoning, satellite instances can be demarcated into their own secure zones to report to a central NOC. Satellites can be simple checkers or fully equipped with local MySQL database, user interface and other extensions too. Replication can be isolated to occur only between the master zone and each individual satellite, keeping satellite sites blind to one another. If a satellite goes rogue, check results are saved for retroactive replication access once the connection is restored.
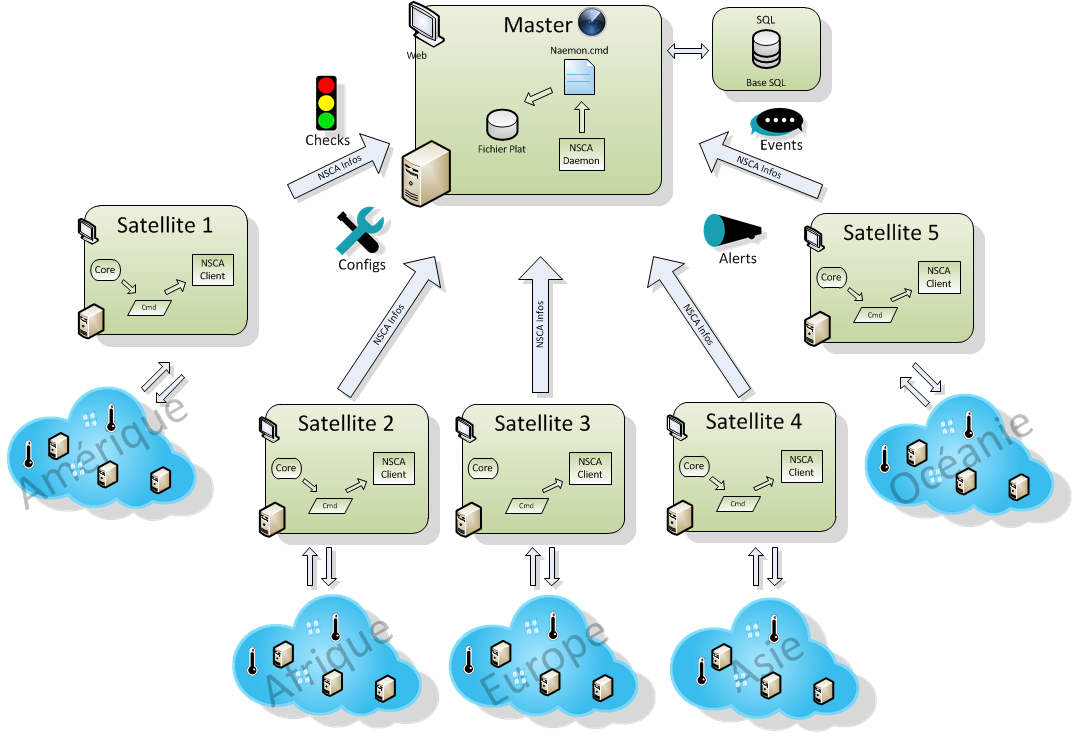
Distributed, high availability monitoring¶
Combine high availability clusters with a distributed setup, and you have a best practice scenario for large and complex environments. Satellite nodes can be scaled to form high availability clusters and cordoned off into secure zones. Load balancing and replication within them can be managed by an active zone instance to reflect different levels of hierarchy. An instance in the satellite zone can be a simple checker, sending results to the active satellite node for replication and display on a local interface. In turn the active satellite node can relay results to the NOC master zone for global reports.
Important
TODO Put all of the Naemonbox supervisory parameters with formulas and examples.
Diagrams¶